
Hello, there! I am a recent graduate with an MS degree (Thesis Track) in the Computer Science Department at Virginia Tech (VT), where I was advised by Dr. Xuan Wang. I was also a member of the Sanghani Center for Artificial Intelligence and Data Analytics at VT. My primary research interests lie in Natural Language Processing (NLP), Large Language Models (LLMs), Multimodal AI, and AI for Healthcare. My thesis focused on developing and fine-tuning multimodal foundation models specifically designed for scientific and biological applications.
I obtained my Bachelor’s Degree in Computer Science (CS) from Indian institute of Technology, Bombay (IIT Bombay).
Prior to VT, I worked as a Senior ML engineer with 5 years of experience in Big Data and Machine Learning. In my role at a multinational AI company, I worked with Fortune 500 companies like P&G (Consumer Goods), IdeaForge (Drone Technology), Sky (Telecom Media), DLG (Insurance), and Visa (Financial Services). My work involved leveraging their structured/unstructured data to build intelligent AI systems using cutting-edge machine learning & deep learning frameworks.
Academic Service
Reviewer : ACL’25, ISMB’25, IEEE BigData’24, EMNLP’24
News
- [2025.05] Successfully defended my Master’s Thesis on Network-Guided Large-Scale Foundation Models! What an amazing journey! Thesis
- [2025.04] Honored to be recognised as the finalist for the 2025 Paul E. Torgersen Graduate Student Research Excellence Award! TorgersenGradAward
- [2025.03] My first-author paper got accepted to the ISMB 2025 main conference proceedings! (to appear in Bioinformatics journal, acceptance rate: 17.5%). Congrats to all my co-authors! Read the preprint on bioarXiv
- [2025.02] Check out our new survey paper on Trustworthiness of LLMs in Healthcare!
- [2024.10] Excited and Grateful to receive an award from NSF NAIRR Pilot to support our research on network-regulated large language models for multi-omics data.
- [2024.08] Presented my research poster at the Amazon - VT Initiative for Efficient and Robust Machine Learning event.
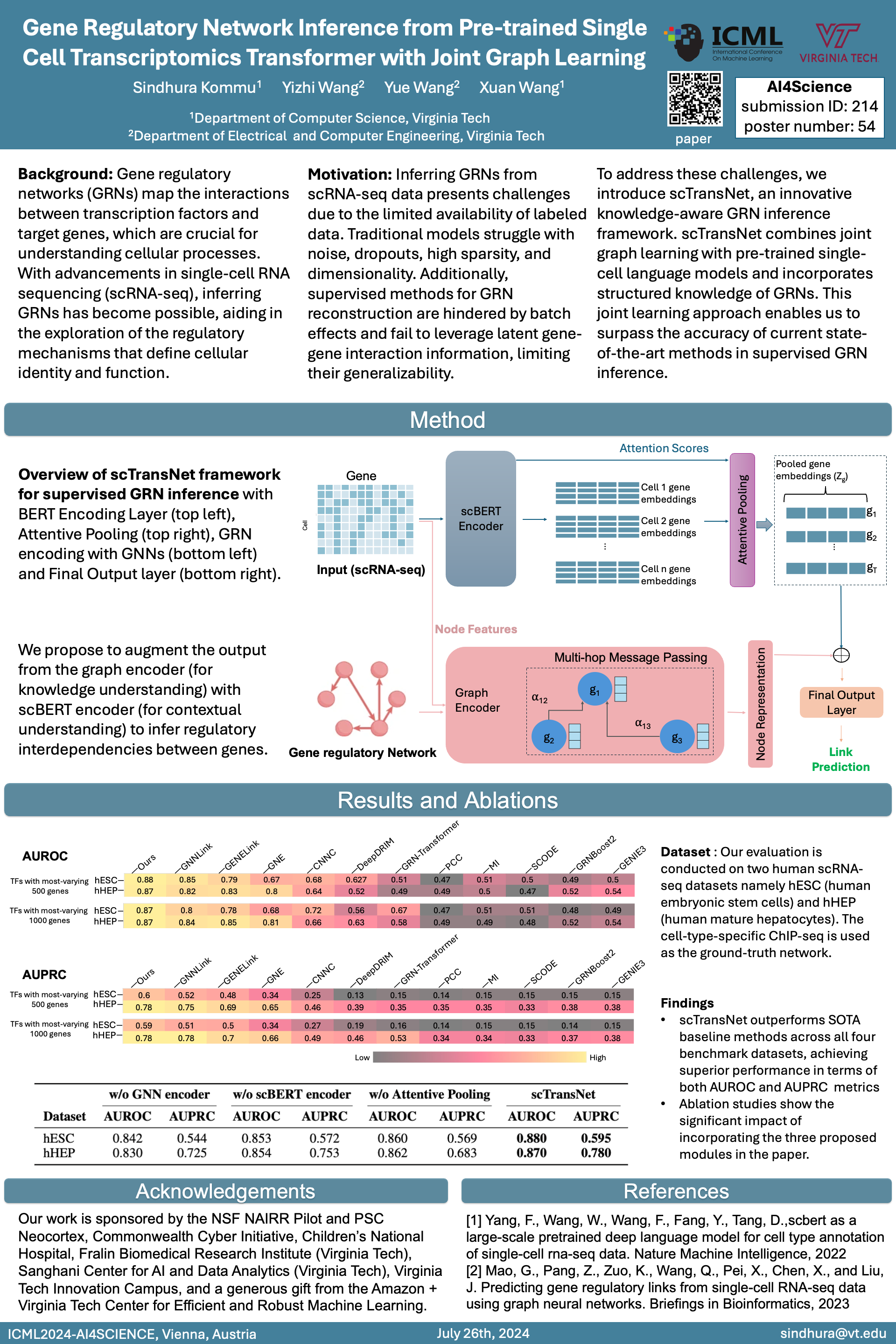
- [2024.06] My first-author paper on joint graph learning is accepted by ICML 2024 AI4Science: paper; poster. Congrats to my collaborators!
- [2024.04] Thrilled for being awarded the AnitaB.org Advancing Inclusion Scholarship to attend the Grace Hopper Celebration (GHC) 2024! This prestigious scholarship will allow me to participate in the world’s largest gathering of women and non-binary technologists
- [2024.03] Check out our new survey paper on LLMs for diverse biomedical data! We explored three critical categories of biomedical data: 1) textual data (biomedical literature and health records), 2) biological sequences (DNA/RNA/protein sequences and multi-omics sequencing data), and 3) brain signals (time-series EEG data).
{kind=link}